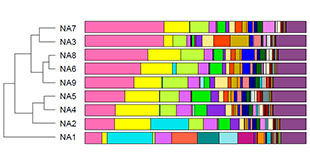
显著性差异分析[1](Differentially Abundant Features)根据得到的群落丰度数据,运用严格的统计学方法可以检测两组微生物群落中表现出丰度差异的分类,进行稀有频率数据的多重假设检验和假发现率(FDR)分析可以评估观察到的差异的显著性。分析可选择门、纲、目、科及属等不同分类学水平。
使用软件:利用matastats [2](http://metastats.cbcb.umd.edu/)对不同分类学水平进行的两组样本进行显著性差异分析,同时整理了高分类学水平中包含的低分类学水平的物种的显著性差异情况。
参考文献:
[1] Tingting Wang, Guoxiang Cai, et al. Structural segregation of gut microbiota between colorectal cancer patients and healthy volunteers. The ISME Journal advance online publication, 18 August 2011;doi:10.1038/ismej.2011.109.
[2] White, J.R., Nagarajan, N. & Pop, M. Statistical methods for detecting differentially abundant features in clinical metagenomic samples. PLoS Comput Biol 5, e1000352 (2009).
例表:
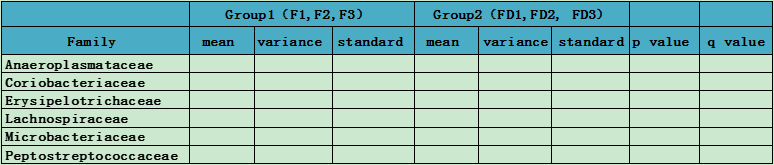
注:mean:均值; variance:方差; standard:标准差;
p value (an individual measure of the false positive rate) 假阳性概率值,是统计学中常用的判定值,一般来说P value<0.05 时差异显著;
q value (an individual measurement of the false discovery rate) 假发现率评估值,指本次计算可信度。
多水平整理表如下所示:
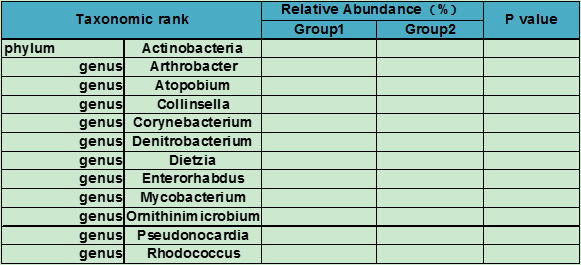
注:表中同时计算了门水平及其包含的属水平在两组样本中的显著性差异情况。